Eight

The move firmly positions Data61’s Machine Learning Research Group as an international thought leader in machine learning.
“As a group, we feel proud and excited about this achievement,” says Dr Edwin Bonilla, Principal Research Scientist and Team Leader at Data61’s Machine Learning Research Group.
“The diverse range of topics in our accepted papers at NeurIPS shows that we cover both fundamental research as well as applied work, addressing theoretical challenges such as understanding regularisation and distributional robustness; algorithmic developments such as better probabilistic inference algorithms and robust approaches to adversarial learning; and high-impact applications in computer vision and sign language translation.”
Two of the papers have been selected for a Spotlight Presentations (only 3% of all submission were awarded this opportunity), with authors to present their findings to an international audience of machine learning experts.
NeurIPS brings together thousands of specialists annually to share the latest artificial intelligence and machine learning research and discuss key issues.
Google, Microsoft, Tesla, Facebook, Stanford and MIT are among the big tech names that attend the conference, which attracted over 13,000 attendees last year.
53 Australian papers were accepted this year, placing Australia in seventh position overall. Australia’s continued excellence and participation in NeurIPS resulted in a successful bid to host the 2021 conference in Sydney.
Please join us in congratulating the Machine Learning Research Group and all team members involved in this tremendous achievement!
Papers featuring authors from Data61’s Machine Learning Research Group include:
- Spotlight Presentation, Variational Inference for Graph Convolutional Networks in the Absence of Graph Data and Adversarial Settings: Dr Pantelis Elinas (CSIRO’s Data61), Dr Edwin V. Bonilla (CSIRO’s Data61), Mr Louis Tiao.
- Spotlight Presentation,PAC-Bayesian Bound for the Conditional Value at Risk: Mr Zakaria Mhammedi, Dr Benjamin Guedj, Prof Robert Williamson
- TSPNet- Hierarchical Feature Learning via Temporal Semantic Pyramid for Sign Language Translation: Mr Dongxu Li, Mr Chenchen Xu, Dr Xin Yu, Mr Kaihao Zhang, Dr Ben Swift, AsProf Hanna Suominen, and Prof Hongdong Li.
- Quantile Propagation for Wasserstein-Approximate Gaussian Processes: Dr Lexing Xie, Mr Rui Zhang, Dr Christian Walder, Dr Edwin V. Bonilla, Dr Marian-Andrei Rizoiu.
- LEAStereo- Learning Effective Architectures for Deep Stereo Matching: Ms Xuelian Cheng, Mr Yiran Zhong, Dr Mehrtash Harandi, Dr Yuchao Dai, Dr Xiaojun Chang, Prof Hongdong Li, Prof Tom Drummond, and Dr Zongyuan Ge.
- All your loss are belong to Bayes: Dr Christian Walder and Prof Richard Nock
- Distributional Robustness with IPMs and links to Regularization and GANs: Mr Hisham Husain
- Learning the Linear Quadratic Regulator from Nonlinear Observations: Mr Zakaria Mhammedi, Mr Dylan J. Foster, Mr Max Simchowitz, Mr Dipendra Misra, Mr Wen Sun, Dr Akshay Krishnamurthy, AsProf Alexander Rakhlin and Dr John Langford
Spotlight Presentation: Variational Inference for Graph Convolutional Networks in the Absence of Graph Data and Adversarial Settings
Graph convolutional networks (GCNs) are a popular type of neural network that utilise relationships across instances to improve predictions.
For example, to predict a user’s preferences on a social platform, their interactions with other members in their network, such as friends, could reveal insights into their preferences. The users and their interactions can be represented as a set of vertices (also called nodes) and edges, respectively, forming a structure commonly referred to as a graph.
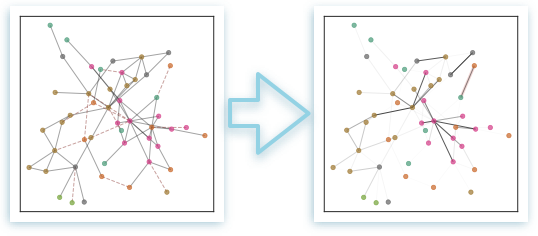
This new approach enables GCNs to learn new graph representations from scratch (i.e. in the absence of a graph) or when the edges of the graph have been corrupted by adversarial noise.
By adopting a Bayesian approach and formulating a joint probabilistic model on the graph and its observations, new representations can be learned by estimating a posterior probability distribution over the graph following a technique known as stochastic variational inference.
This novel method outperforms state-of-the-art Bayesian and non-Bayesian graph neural network algorithms in problems such as predicting the category of scientific publications and uncovering the political affiliation of blog posts.
This approach could have a significant impact in areas such as detecting online hate speech and understanding fake news in social media.
Read the paper here.
Spotlight Presentation: PAC-Bayesian Bound for the Conditional Value at Risk
Generalisation bounds are crucial for understanding the theoretical properties of a machine learning algorithms’ performance.
This research provides a generalisation bound for learning algorithms that minimize the Conditional Value at Risk (CVAR) of the empirical loss instead of its expectation. CVAR is a risk assessment measure widely used in mathematical finance.
The research also derives new concentration bounds for CVAR by reducing the problem of estimating CVAR to that of simply estimating expectations using empirical means, even when the random variable in question is unbounded.
This work can have a broader impact in applications where minimising the standard expected risk is undesirable, such as medical or environmental applications.
CVAR belongs to the family of coherent risk measures linked to the concept of fairness in machine learning algorithms, with this new methodology providing a promising direction into the design of objective algorithms.
Read the paper here.
TSPNet: Hierarchical Feature Learning via Temporal Semantic Pyramid for Sign Language Translation
By exploring and incorporating temporal and semantic sign language structures in videos, this proposed language translation tool can interpret sign video sequences into text-based natural language sentences.
The first of its kind, this machine learning-driven tool considers multiple temporal granularities that alleviate the need for accurate video segmentation. The result is a hierarchical sign video feature learning method via a temporal semantic pyramid network called TSPNet.
TSPNet introduces an inter-scale attention to evaluate and enhance local semantic consistency of sign segments and an intra-scale attention to resolve semantic ambiguity by using non-local video context. TSPNet provides a significant performance increase from previous state-of-the-art solutions.
This research will play a key role in the future design of automated sign language interpretation systems, eliminating the barrier in communicating with hard of hearing people and promoting public awareness of equitable distribution of health, education, and economic resources in a broader society.
Read the paper here.
Quantile Propagation for Wasserstein-Approximate Gaussian Processes
In contrast to standard deep neural networks, probabilistic methods based on Gaussian process priors allow for the development of machine learning algorithms that can accurately quantify uncertainty in their predictions.
This research develops a new inference technique for models with Gaussian process priors that can provide better uncertainty estimates than widely used approaches such as expectation propagation (EP) and variational inference.
The proposed method, referred to as Quantile Propagation (QP), is similar to EP, but rather than minimising the standard Kullback-Leibler (KL) divergence, it minimizes the L2 Wasserstein distance, a more natural distance measure between probability distributions.
QP has the same favourable locality property as EP, enabling the development of an efficient algorithm for posterior estimation. Gaussian process models are widely used in spatio-temporal applications in the mineral resources and environment fields.
This research paves the way for more practical and effective inference approaches for these types of models, ultimately enabling the creation of a suite of powerful methods that apply a Bayesian approach to machine learning.
Read the paper here.
LEAStereo: Learning Effective Architectures for Deep Stereo Matching
The first of its kind, LEAStereo is an end-to-end hierarchical Neural Architecture Search (NAS) framework for deep stereo matching that significantly reduces the search space whilst improving the interpretability of the resulting network.
By leveraging task-specific human knowledge in the method’s architecture, LEAStereo not only avoids the demands of computational resources when searching architectures for high-resolution dense prediction tasks, but also achieves better accuracy compared to searching an architecture in a large search space.
This novel solution has outperformed all state-of-the-art deep stereo matching architectures (handcrafted and NAS searched) and is ranked first for accuracy on KITTI 2012 stereo and Middlebury 2015 benchmarks, showcasing a substantial improvement in network size and inference speed.
Stereo matching is a classic computer vision problem important in many tasks such as autonomous driving, robotics and 3D scene reconstruction.
Predicting depth using visual sensory is an essential skill for both animals and humans and is a required component for autonomous cars that will use it to estimate distance from visual sensor data.
This new method will enable more robust and reliable designs of neural networks.
Read more about this research here.
All your loss are belong to Bayes
According to researchers in Data61’s Machine Learning Research Group, the almost unforgivable grammatical errors displayed in the title of this paper are very much intentional, having been inspired by a famous quote from statistical learning theory pioneer Vladimir Vapnik (see here).
This approach explores a new perspective on learning loss functions, with the authors adopting a Bayesian approach to inferring a posterior distribution over loss functions for supervised learning.
This methodology utilises
Despite its generality, this technique surpasses state-of-the-art and even the most classic baseline of binary classification using the logistic loss.
While machine learning enables a system to learn and make decisions based on the data it has gathered, that system is still unable to learn the ‘whole’ picture of the problem at hand.
This research could make this a feature of the past, enhancing machine learning systems’ ability to make improved predictions, and therefore actions, regarding complex problems.
Read the full paper here.
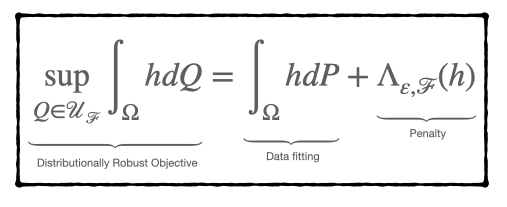
Distributional Robustness with IPMs and links to Regularization and GAN
Neural networks are particularly susceptible to adversarial attacks due to their complexity, however, a new method known as Distributionally Robust Optimisation (DRO) can effectively mitigate this issue.
DRO studies robustness via divergence-based uncertainty sets, providing valuable insights into robustification strategies such as regularisation. Unlike similar approaches, DRO’s method extends beyond f-divergences, Wasserstein distances and Maximum Mean Discrepancy (MMD) to construct uncertainty sets, using Integral Probability Metrics (IPMs) instead.
Results from this research have shown
Generative Adversarial Networks (GANs) are a machine learning tool is a tool used in several applications, such as text-to-text translation and face frontal view generation.
Using this new methodology, GANs can become more robust against adversarial attacks, particularly those that target image-based applications of machine learning, an area where GANs are frequently deployed.
Read the paper here.
Learning the Linear Quadratic Regulator from Nonlinear Observations
Addressing the problem of continuous control with linear dynamics, quadratic cost and high-dimensional non-linear observations (such as images from a camera), this research provides the first provable sample complexity guarantee for continuous control with an unknown nonlinearity in the system model and general function approximation.
Known as a rich observation linear quadratic regulator (RichLQR), the system’s corresponding algorithm (RichID) can learn a near-optimal policy for RichLQR with sample complexity scaling only with the dimension of the latent state space and the capacity of the decoder function class.
This research is particularly essential for perception-based control systems, which are deployed in applications such as autonomous driving and aerial vehicles where algorithmic errors can have catastrophic consequences.
By improving our understanding of the foundations of perception-based control, this research can help develop tools and techniques to ensure the safety, reliability and robustness of these systems.
Read the paper here.