A photographed handwritten note on paper showing a goal statement. The text reads: “GOAL: To find a real problem in the [space] that we can solve in [time] with technology that delivers measurable value that a customer will pay for.” Key words like real problem, technology and measurable value are highlighted with orange boxes. Dotted arrows point from "our innovation" toward technology and "user + buyer" to real problem. From the phrase "will pay for" a dotted line leads down toward a drawn dollar sign ($). From the word "measurable" a dotted line leads to the right of the main text where there is a vertical list with plus signs and the words better, faster, cheaper and more accurate, written in black. The style is informal and sketched, using black handwriting with orange highlights.
Any founder, product manager or user experience (UX) designer will tell you that the key to building products that people want is to first find the right problem to solve.
Many of the product and design frameworks that have come to life over the past decade concentrate on human-centred design, and begin with a customer problem. But what if you are starting from the other end of the spectrum, with a technology in hand looking for a problem to solve?
While this approach appears contrary to contemporary product design, a ‘tech push' scenario can play out in many ways:
- Existing product company expanding into a greenfield market
- New infrastructure technology looking for an entry use case
- Deep technology looking for an entry use case
- Product teams looking to pivot.
As a product and UX(user experience) team CSIRO's Data61, the data and digital specialist arm of Australia's national science agency, we often find ourselves looking at how we can take deep tech — which could be applied to multiple problems and multiple markets — and determine a problem-to-tech match that provides a real solution pathway.
How is deep tech product genesis different?
A 2019 BCG and Tomorrow World report found that deep tech companies take on average 1.8 years to go from incorporation to first prototype, and a further 1.5 years to go from prototype to market. Add to this that in research organisations, it can take years to transition from basic research to applied research and early proof of concept development.
A horizontal bar chart titled Exhibit 10 – The Average Time Required from Incorporation to Market Varies by Technology. The chart compares six different technology categories and shows the average number of years it takes from company incorporation to prototype and then from prototype to market. Each category has a stacked bar consisting of two colored segments: From left to right, the technology categories and their time values are: The vertical axis on the left shows time in years from 0 up to 4.5 with tick marks at 0.5 increments. Below the chart is a source note indicating the data comes from the Hello Tomorrow Challenge and BCG analysis of startups, noting it is based on data from 1,500 startups assessed on innovation, business model, team skills, and impact.
We have found that in many cases the right amount of discovery work can enable a deep tech program to zero-in on their problem space much earlier in the process.
This can be particularly helpful if the ecosystem is still in early development, or the innovation so disruptive that the target market doesn't exist yet.
The ‘tech push' of deep tech
Deep tech products and businesses are those founded on a scientific discovery or meaningful engineering innovation, characterised by:
- having a big impact; like creating new markets, instigating social/environmental change
- taking a long time to reach market-ready maturity
- requiring a significant amount of capital to develop and scale (source).
The very nature of deep tech is to generate disruptive innovation. As such, the products and businesses arising from deep tech are often market creators (i.e Internet of Things (IoT)), or can be transformative to multiple market problems (i.e. machine learning, quantum computing).
In a traditional research and development environment the creation of deep tech produces a ‘tech push' where the challenge is to find the right problem to solve with the technology. Because deep tech can be applied so broadly, finding the right problem-to-innovation match to deliver both impact potential and a solution pathway is complex.
A simple circular flow diagram illustrating the four key stages of a design sprint or iterative innovation process. The diagram consists of a faint grey circular arrow forming a loop, with four labelled points evenly spaced around the circle. Starting at the top-left and moving clockwise, the stages are: A thicker teal curved line connects the Idea stage directly to the Learn stage, emphasizing a streamlined loop between these two points rather than following the full circular path. The effect suggests a rapid cycle from idea to learning possibly facilitated through experimentation or prototyping, a hallmark of design sprint methodology. The image source, GV.com is credited at bottom centre of the image indicating the source. 
Discovering the perfect problem
This particular Data61 program focused on the building of graph machine learning technology, a program that is now known as Stellargraph. The potential applications for this technology are numerous; whenever there is a large dataset with interconnected data, graph analytics can provide deeper insights, faster.
So when you can go anywhere; where do you start?
We chose to start with some early discovery work to flesh-out our assumption that Stellargraph's innovation could be applied in the sophisticated financial crime problem space. To validate these assumptions we worked our way through the following steps:
- Understand the innovation — determine what the tech does (the output), and the outcome of this (the abstract). Map out the technical capability needed to make the innovation fit-for-purpose.
- Background research — review the associated industry landscape and develop a macro-level view of the ecosystem and all the actors in it. This might include things like industry talks, conferences and customer discovery activities.
- Business idea generation — document a range of global trends and match them to your innovation to ideate what the market problem/benefit could be.
- Discovery activities —unearth the context, current state and problems with research activities such as customer and user interviews, surveys, jobs-to-be-done analysis.
- Validation exercises — match the problems with potential solutions, conducting early concept exploration and testing with customers and users.
These steps that enabled our the user experience (UX) and product teams to ‘front load' domain exploration to provide a solid grasp of the ecosystem of a given market or industry sector — as well as the technologies being used in it — to generate insight into the business and user needs that are not yet solved by existing technology.
A hand written note on graph paper showing two main points of the discovery phase when building problem-solution technology. Output - Saliency maps, using gradient-based estimates of node importance and link importance on the outcome of predictions on graphs. Outcome - Users can interpret which data was more important in a recommendation.
The discovery validation phase
Having completed the domain groundwork using the above steps, using the Design Sprint methodology in a discovery context was an effective validation exercise that accelerated the problem-to-innovation fit process.
In keeping with the Design Sprint methodology, a full five-day process was undertaken to investigate a future product scenario with the aim to better understand technology proposals, allow any possible risks to surface, and quantify possible opportunities by contrasting them to the current landscape.
Through this process, we found a problem was discovered that required this particular application of deep tech to solve it.
Learnings from our discovery phase
Warm up before you sprint
The Design Sprint methodology starts with the assumption that teams already have expertise in their problem space, and that the first day will be sufficient to bring everyone up to a common understanding. But in a tech push environment, this is rarely the case.
It was critical in the discovery phase to put aside two to eight weeks to adequately cover all the areas needed to build a working understanding of the problem space before launching into the Design Sprint.
In this case, the project was investigating if graph machine learning could be used in the sophisticated financial crime problem space. As the team were not domain experts, they worked through discovery steps one, two and four to build the following context:
- Understand the innovation by abstracting the technology from output to outcome to map out the keystone capability. The below is an example of a technical output abstracted to a business outcome:
- Background research including building an understanding of both industry and government perspectives, including a survey of the legal landscape and expert interviews.
- Discovery activities based on organisation versus user challenges, Jobs to be Done (JTBD), user personas, and researching how people can trust and therefore act on machine learning predictions in high consequence situations (stay tuned for our upcoming article on trust in machine learning).
Venn diagram comprising three overlapping circles, each representing a different lens used in innovation and design thinking for evaluating ideas. The three circles are arranged so that all three intersect in a central area where they overlap together, forming a shared space at the middle. Each circle overlaps with the other two, creating three pairwise overlapping areas and a central intersection where all three meet. The central overlapping area — where Desirability, Feasibility, and Viability all intersect — is labelled Our discovery sprint and represents the ideal zone for innovation: solutions that are wanted by users, technically feasible, and economically viable. 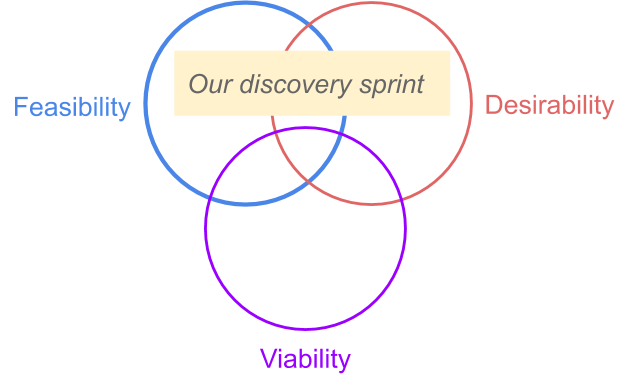
Be clear on buyer/user scope
If an innovation is an enterprise product, be aware of the difference between the buyer, and the user. With consumer products, buyers and users are typically one and the same; this is not always the case with enterprise products.
Distinguish user and buyer personas to make it clear which one to focus on from day one of the Design Sprint. By the fifth day, it should be clear whether the chosen persona would want to use and/or pay for the product.
During the problem-fit testing stage, the team narrowed their scope to test desirability and feasibility only ,focusing on potential users, not buyers.
This meant if the design sprint showed that the innovation didn't provide feasibility-desirability,pivoting the innovation to another use case was possible. However, if strong positive indications were generated, viability would need to be tested for in a second round of validation exercises.
Use low fidelity prototypes when testing deep tech concepts
In this project, the core goal was to validate the desirability of the innovation and whether potential users would employ this type of technology for their JTBD.
Therefore, day five of the user testing component was focused on validating the value the innovation would provide for users rather than getting distracted with its visual elements. This meant:
- low fidelity sketch prototypes — pencil on paper, no colour
- targeted questions around validating the value.
The team found that a low fidelity approach for deep tech concept testing helped keep participants focused on the tasks presented to them, mitigating visual distractions and users getting stuck on the interaction detail.
Recruit testing participants early
The success of any sprint depends on having the right mix and right number of participants for day five testing.
Ideally, five participants are needed, all of whom are homogenous and match the persona you are targeting for the innovation.
For specialised or enterprise products, you will be looking for participants who have specialised skills or qualifications. These experts can be much harder to find and/or engage in testing due to confidentiality/security concerns, as well as availability during business hours.
Many of the participants who supported our discovery phase fall into this category, so we found initiating the recruiting ahead of the Design Sprint by several weeks critical to our success in getting the right participants.
In summary
In the tech push environment, the discovery phase and Design Sprint process are valuable tools to either fail fast, or accelerate the deep tech to a level of disruptive innovation and market creation.
While the viability of this particular innovation still needed to be validated, the discovery phase and Design Sprint process demonstrated the value of combining product and UX approaches to validate the problem-solution fit early in the process.
The learnings extracted set the foundation for further adaptation of the Design Sprint framework to suit the tech push environment.
Have you used design sprints in a discovery phase for deep tech or to build enterprise systems? We'd love to hear from you — please share your experience as a comment below.
The StellarGraph Library is an open source python library that delivers state of the art graph machine learning algorithms on Tensorflow and Keras. To get started, run pip install stellargraph, and jump in to one of the demos.
This work is supported by CSIRO's Data61, Australia's leading digital research network.