The end of 2021 was a joyful occasion for many, not least the D61 researchers whose papers were accepted by NeurIPS – the largest and most prestigious machine learning conference on the planet. The virtual December conference attracted attendance from technology giants such as Microsoft, Google and world-leading universities who came together to further advance the field of Neural Information Processing Systems.
Papers covered a range of topics, from using deep reinforcement learning to prove theorems from scratch, to deep learning and model selection. Read on to learn more about each paper accepted to the conference.
TacticZero: Learning to Prove Theorems from scratch with Deep Reinforcement Learning
by Minchao Wu, Michael Norrish, Christian Walder, Amir Dezfouli
“In maths,” explains Amir Dezfouli, “a theorem is a statement which can be proved. You may have heard of some famous theorems, such as Pythagoras' theorem, which has been proved countless times and in different ways over the thousands of years since it was discovered.
“Many areas of science, and in particular mathematics, require theorem proving. Due to its complexity, theorem proving is often carried out by human experts.
“Here we asked whether artificial intelligence (AI) could learn to prove theorems from scratch without any inputs from humans.
“We used reinforcement-learning to answer this question and developed a new framework to automate theorem proving. Using this approach, we found that our algorithm can indeed achieve high performance in the task, even compared to the alternative methods that leverage human input.
“The team are excited with this result because mathematical derivations are fundamental to many areas of science. Making them automated using machine learning could help researchers speed up their discoveries,” said Amir.
Visit NeurISP Proceedings to read the paper.
Contrastive Laplacian Eigenmaps
by Hao Zhu, Ke Sun, Piotr Koniusz
Neuroscience tells us something profound about the brain. The brain is a universal learner and can adapt rapidly to very different modalities, problems and realities.
“Take the amazing neuroplasticity of the brain: it turns out that regions processing language can easily adapt to process sound in people with a brain injury,” explains Piotr Koniusz.
“Regions involved in image reasoning can take on other unrelated modalities.
“With this kind of adaptive processing in mind, we set out to discover a universal fast learning technique that can learn on graphs with limited labelling. We wanted to find out if the celebrated Graph Laplacian Embedding method can perform better if universal learning theory was applied to utilise not only the graph connectivity information but also the so-called contrastive learning based on random sampling.”
Contrastive learning is a form of self-supervised learning. Imagine a system that learns to predict some easily obtainable properties of data rather than learning target labels annotated by humans, which are costly to obtain.
Predictive coding - one prominent example of a self-supervised learning paradigm - can also be seen in the way humans learn when they try to predict the future and calibrate for prediction error.
We found that it was indeed possible to revive this classical machine learning idea in the contrastive setting, and under our assumptions, COntrastive Laplacian EigenmapS enjoys some hot information-theoretic interpretation which explains why it learns better representations on complicated graphs.
In this paper, we extend Laplacian Eigenmaps with contrastive learning, and call them COntrastive Laplacian EigenmapS (COLES). Starting from a GAN-inspired contrastive formulation, we show that the JensenShannon divergence underlying many contrastive graph embedding models fails under disjoint positive and negative distributions, which may naturally emerge during sampling in the contrastive setting.
In contrast, we demonstrate analytically that COLES essentially minimises a surrogate of Wasserstein distance, which is known to cope well under disjoint distributions. Moreover, we show that the loss of COLES belongs to the family of so-called block-contrastive losses, previously shown to be superior compared to pair-wise losses typically used by contrastive methods. We show on popular benchmarks that COLES offers favourable accuracy/scalability compared to DeepWalk, GCN, Graph2Gauss, DGI and GRACE baselines.
Using these techniques, we expect companies - and the public sector - may be able to reduce annotation costs, increase the speed of their data processing and therefore reduce their carbon footprint.
Visit NeurIPS Proceedings to read the paper.
On the Variance of the Fisher Information for Deep Learning
by Alexander Soen and Ke Sun
Fisher information is a key concept in traditional statistics that measures how much information about an unknown variable can be derived from a sample.
In the area of deep learning, each neural network is associated with a Fisher information matrix (FIM). One can think of the FIM as a "signature" of the network, which describes its intrinsic properties. When the network weights change, the signature also changes.
“Almost all current approaches in deep learning estimate the FIM using a random estimator (a random matrix),” said Dr Ke Sun.
“We saw a huge opportunity to study the estimation quality to improve accuracy in the field.”
In this theoretical work, the collaborators discover the variance of two commonly used FIM estimators in deep learning. The team describe how accurate these random matrices are with respect to the underlying true FIM and discuss how they can be affected by the deep neural network structure.
“Our results are universal in the sense that regardless of the application and specifics of the network architecture, one can always use our results to more accurately estimate the FIM. Consequently, one can more efficiently train the neural network, and compute quantities that are important to understand how deep learning works,” said Ke.
Visit NeurISP Proceedings to read the paper.
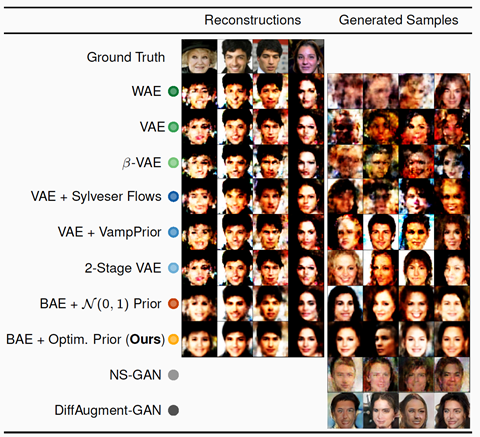
Model Selection for Bayesian Autoencoders
by Ba-Hien Tran, Simone Rossi, Dimitrios Milios, Pietro Michiardi, Edwin V. Bonilla, Maurizio Filippone
Autoencoders are popular deep learning algorithms that are trained to replicate input. Although seemingly trivial, creating useful autoencoders continues to be an active area of research. Autoencoders have found important applications such as learning generic and transferable representations that can be used in downstream tasks like classification, dimensionality reduction, information retrieval, image generation and even medical imaging (e.g. breast cancer detection).
One of the most difficult settings for training autoencoders successfully is when the data is scarce and quantification of uncertainty is critical, like medical imaging. In this setting, a well-founded approach is that of Bayesian modelling, hence the name of Bayesian autoencoders (BAE), where a prior probability distribution is placed over the autoencoder parameters. Although mathematically elegant, two fundamental problems remain with this approach: (i) how to set up good priors and (ii) how to carry out the estimation of the posterior probability distribution over the autoencoder parameters after observing data. The former problem is referred to as model selection and the latter as posterior estimation. These are particularly hard problems, especially when the input has very high dimensions, such as a high-resolution image.
The team developed a novel method to tackle the problems by optimising the prior parameters (known as hyper-parameters) via the minimisation of the distributional sliced- Wasserstein distance (DSWD) between the output of the autoencoder and the empirical data distribution.
The main advantage of this formulation is that the DSWD can be estimated efficiently based on samples even for high-dimensional problems. Furthermore, we developed a fast algorithm for posterior estimation based on stochastic gradient Hamiltonian Monte Carlo.
The proposed approach was evaluated qualitatively and quantitatively using a vast experimental campaign on several learning tasks including image generation and reconstruction. It was shown that the proposed method provides state-of-the-art results, outperforming multiple competitive baselines.
Visit NeurISP Proceedings to read the paper.